Robots.txt is an important text file ( .txt ) saved in the root directory of your site. It guides search engine spiders ( or robots ) which links in your site will be allowed for crawling and which are not. Its URL is usually denoted by “http://www.yoursite.com/robots.txt.

In search engine optimization ( SEO ), robots.txt aids in managing links from one page of your site to others. This will be highly practical when there are so many irrelevant pages linked on every page of your site. Note that the time for search engine robots to crawl pages from your site is limited. So it is better that every page they are going to crawl will be highly relevant and having good content about the topics and keywords you are targeting in SEO.
To appreciate more deeply the functions of robots.txt for your site, the following steps can give you insights :

In search engine optimization ( SEO ), robots.txt aids in managing links from one page of your site to others. This will be highly practical when there are so many irrelevant pages linked on every page of your site. Note that the time for search engine robots to crawl pages from your site is limited. So it is better that every page they are going to crawl will be highly relevant and having good content about the topics and keywords you are targeting in SEO.
To appreciate more deeply the functions of robots.txt for your site, the following steps can give you insights :
- Open a Notepad and name it as robots.txt ( note the extension .txt to denote that it is a text file ).
- Gather all folders, files or pages you don’t want search engine robots to crawl.
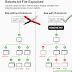
- Type-in " User-agent: * " in you robots.txt file. This will be the default syntax to address all robots from different search engines. You can also address specific search engine robots with “ User-agent: search engine robot code ( e.i googlebot ). ” Just beware that when you are addressing specific search engine robots, there must be an accompanying “Disallow” statement (if any) corresponding each " User-agent " statement. So using " User-agent: * " is a safer choice. You can refer to the following example:
- User-agent: *
- User-agent: googlebot
- User-agent: *
- Type-in " Disallow: /folder name " for any folder containing files you don’t want search engines to crawl. Or type-in " Disallow: /filename.filetype " for any page or file you don’t want search engines to index. Note of the following example :
- Disallow: /private/
- Disallow: /private/image01.jpg
- Disallow: /private/
- As a warning, " Disallow: / " syntax directs search engine robots not to crawl any page from your site. So use the syntax " Disallow: " instead if you want search engine robots to index any page from your site.
- "Allow" syntax does not exist. So do not use this command attempting to instruct search engine robots to crawl a particular folder or file for exceptions.
- Finally, upload this robots.txt file in your site’s root directory.
How to Use Robots.txt in Search Engine Optimization ( SEO )
 Reviewed by Unknown
on
7:09 AM
Rating:
Reviewed by Unknown
on
7:09 AM
Rating:
Reviewed by Unknown
on
7:09 AM
Rating:



{kind=link}
No comments:
Post a Comment